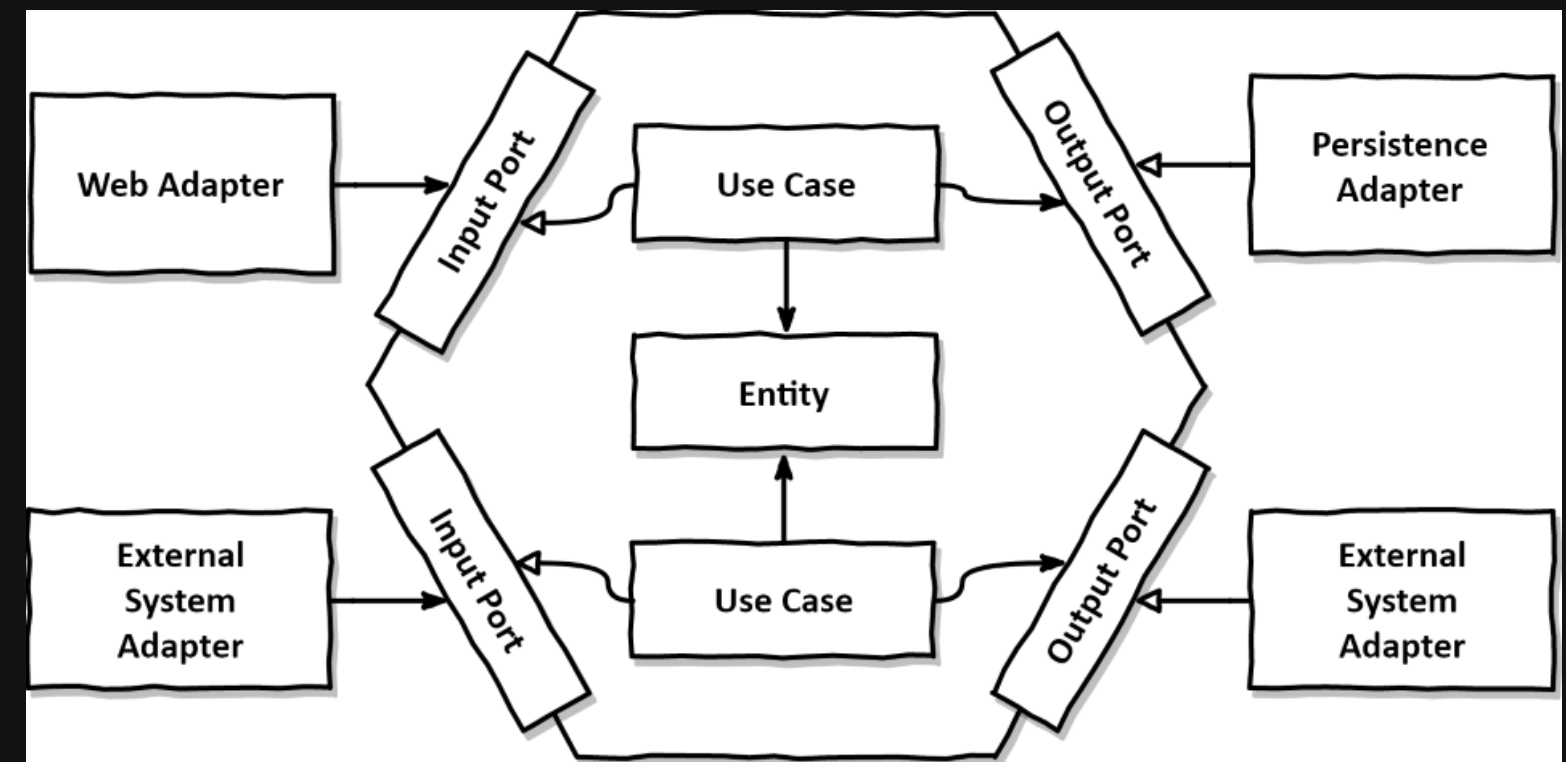
만들면서 배우는 클린 아키텍처 책을 읽고 정리하며 소감을 적는 포스트입니다.
도메인 모델 구현하기
애플리케이션, 웹, 영속성 계층이 현재 아키텍처에서 느슨하게 결합대 있기 때문에 필요한 대로 도메인 코드를 자유롭게 모델링할 수 있다. DDD 개념을 적용하거나, rich or anemic 도메인 모델을 구현할 수도 있고, 새로운 방식을 만들어 낼 수도 있다.
이제 헥사고날 스타일에서 유스케이스를 구현하기 위한 방법을 살펴보자. 도메인 중심 아키텍처에 적합하므로 도메인 엔티티를 만드는 것을 시작으로 유스케이스를 구현해 보자.
계좌 송금 유스케이스
계좌에서 다른 계좌로 송금하는 유스케이스를 구현해 보자. 객체지향적인 방식으로 모델링하는 방법 중 하나는 입금과 출금을 할 수 있는 Account 엔티티를 만들고 출금 계좌에서 출금해서 입금 계좌로 돈을 입금하는 것이다.
package buckpal.domain;
@AllArgsConstructor
@Getter
public class Account {
private AccountId id;
private Money baselineBalance;
private ActivityWindow activityWindow;
// 생성자와 게터 생략
public Money calculateBalance() {
return Money.add(
this.baselineBalance,
this.activityWindow.calculateBalance(this.id)
);
}
public boolean withDraw(Money money, AccountId targetAccountId) {
if (!mayWithDraw(money)) {
return false;
}
Activity withDrawal = new Activity(
this.id,
this.id,
targetAccountId,
LocalDateTime.now(),
money
);
this.activityWindow.addActivity(withDrawal);
return true;
}
private boolean mayWithDraw(Money money) {
return Money.add(
this.calculateBalance(),
money.negate()
).isPositive();
}
public boolean deposit(Money money, AccountId sourceAccountId) {
Activity deposit = new Activity(
this.id,
sourceAccountId,
this.id,
LocalDateTime.now(),
money
);
this.activityWindow.addActivity(deposit);
return true;
}
}
Account 엔티티는 실제 계좌의 현재 스냅샷을 제공한다. 계좌에 대한 모든 입금과 출근은 Activity 엔티티에 포착된다. 한 계좌에 대한 모든 activity 들은 항상 메모리에 한꺼번에 올리는 것은 좋지 않기 때문에 Account 엔티티는 ActivityWindow(value object)에서 포착한 특정 지난 기간의 해당하는 활동만 보유한다. 계좌의 현재 잔고를 계산하기 위해서 Account 엔티티는 활동창(activity window)의 첫 번째 활동 바로 전의 잔고를 표현하는 기준 잔고(baselineBalance) 속성을 가지고 있다.
총 잔고 = 기준 잔고 + 모든 활동창의 잔고
해당 모델 덕분에 계좌에서 일어나는 입금과 출금은 각각 withdraw(), deposit() 메서드에서처럼 새로운 활동을 활동창에 추가하는 것에 불과하다. 출금하기 전에는 잔고를 초과하는 금액은 출금할 수 없도록 하는 비즈니스 규칙을 검사한다. 이제 입출금이 가능한 Account 엔티티가 있으므로 이를 중심으로 유스케이스를 구현하기 위해 바깥 방향으로 나아가 보자.
유스케이스 둘러보기
먼저 유스케이스가 무슨 일을 하는지 살펴보자. 일반적으로는 다음과 같은 단계를 따른다.
- 입력을 받는다.
- 비즈니스 규칙을 검증한다.
- 모델 상태를 조작한다.
- 출력을 반환하다.
유스케이스는 인커밍 어댑터로부터 입력을 받는다. 이 단계를 왜 입력 유효성 검증으로 부르지 않을까? 저자는 유스케이스 코드가 도메인 로직에만 신경 써야 하고 입력 유효성 검증으로 오염되면 안 된다고 생각하였다. 따라서 입력 유효성 검증은 곧 살펴볼 다른곳에서 처리하는 것을 확인해 보자.
그러나 유스케이스는 비즈니스 규칙을 검증할 책임이 있다. 그리고 도메인 엔티티와 이 책임을 공유한다. 비즈니스 규칙을 충족하면 유스케이스는 입력을 기반으로 어떤 방법으로든 모델의 상태를 변경한다. 일반적으로 도메인 객체의 상태를 바꾸고 영속성 어댑터를 통해 구현된 포트로 이 상태를 전달해서 저장될 수 있게 한다. 유스케이스는 또 다른 아웃고잉 어댑터를 호출할 수도 있다. 마지막 단계는 아웃고잉 어댑터에서 온 출력값을, 유스케이스를 호출한 어댑터로 반환할 출력 객체로 변환하는 것이다.
package buckpal.application.service
@RequiredArgsConstructor
@Transactional
public class SendMoneyService implements SendMoneyUseCase {
private final LoadAccountPort loadAccountPort;
private final AccountLock accountLock;
private final UpdateAccountStatePort updateAccountStatePort;
@Override
public boolean sendMoney(SendMoneyCommand command) {
// TODO: 비즈니스 규칙 검증
// TODO: 모듈상태 조작
// TODO: 출력 값 반환
}
}
서비스는 인커밍 포트 인터페이스인 SendMoneyUseCase를 구현하고, 계좌를 불러오기 위한 아웃 고잉 포트 인터페이스인 LoadAccountPort를 호출한다. 그리고 데이터에비스의 계좌 상태를 업데이트하기 위해 UpdateAccountStatePort를 호출한다.
하나의 서비스가 하나의 유스케이스를 구현하고, 도메인 모델을 변경하고, 변경된 상태를 저장하기 위해 아웃고잉 포트를 호출한다.
입력 유효성 검증
입력 유효성 검증은 유스케이스 클래스의 책임이 아니라고 이야기하긴 했지만, 여전히 이 작업은 애플리케이션 계층의 책임에 해당한다.
호출하는 어댑터에서 입력 유효성 검증?
호출하는 어댑터가 유스케이스에 입력을 전달하기 전에 입력 유효성을 검증하면 어떨까? 유스케이스에서 필요로 하는 것을 호출자가 모두 검증했다고 믿을 수 있을까? 또, 유스케이스는 하나 이상의 어댑터에서 호출될 텐데, 그러면 유효성 검증을 각 어댑터에서 전부 구현해야 한다.
애플리케이션 계층에서 입력 유효성을 검증해야 하는 이유는, 그렇게 하지 않을 경우 애플리케이션 코어의 바깥쪽으로부터 유효하지 않은 입력값을 받게 되고, 모델의 상태를 해칠 수 있기 때문이다. 유스케이스 클래스가 아니라면 어디에서 입력 유효성을 검증해야 할까? 입력 모델(input model)이 이 문제를 다루도록 해보자.
입력 모델에서 입력 유효성 검증
송금하기 유스케이스에서 입력 모델은 SendMoneyCommand 클래스다. 생성자 내에서 입력 유효성을 검증할 것이다.
package buckpal.application.port.in
@Getter
public class SendMoneyCommand {
private final AccountId sourceAccountId;
private final AccountId targetAccountId;
private final Money money;
public SendMoneyCommand(
AccountId sourceAccountId,
AccountId targetAccountId,
Money money) {
this.sourceAccountId = sourceAccountId;
this.targetAccountId = targetAccountId;
this.money = money;
requireNonNull(sourceAccountId);
requireNonNull(targetAccountId);
requireNonNull(money);
requireGraterThan(money, 0);
}
}
송금을 위한 조건 중 하나라도 위배되면 객체를 생성할 때 예외를 던져서 객체 생성을 막으면 된다. SendMoneyCommand의 필드에 final을 지정해 불변 필드로 만들었다. 따라서 일단 생성에 성고하고 나면 상태는 유효하고 이후에 잘못된 상태로 변경할 수 없다는 사실을 보장할 수 있다.
SendMoneyCommand는 유스케이스 API의 일부이기 때문에 인커밍 포트 패키지에 위치한다. 그러므로 유효성 검증이 애플리케이션의 코어에 남아 있지만 유스케이스 코드를 오염시키지는 않는다.
입력 모델에 있는 유효성 검증 코드를 통해 유스케이스 구현체 주위에 사실상 오류 방지 계층(anti corruption layer)을 만들었다. 여기서 말하는 계층은 하위 계층을 호출하는 계층형 아키텍처의 계층이 아니라 잘못된 입력을 호출자에게 돌려주는 유스케이스 보호막을 의미한다.
자바에 Bean Validation API가 이러한 작업을 위한 사실상의 표준 라이브러리다. 해당 api를 이용하면 애너테이션으로 표현할 수 있다.
생성자의 힘
SendMoneyCommand는 생성자에 많은 책임을 지우고 있다. 클래스가 불변이기 때문에 생성자의 인자 리스트에는 클래스의 각 속성에 해당하는 파라미터들이 포함돼 있다. 그뿐만 아니라 생성자가 파라미터의 유효성 검증까지 하고 있기 때문에 유효하지 않은 상태의 객체를 만드는 것은 불가능하다.
그런데 만약 생성자의 파라미터가 더 많다면 어떻게 해야 할까? 빌더 패턴을 활용하면 더 좋지 않을까?
new SendMoneyCommandBuilder()
.sourceAccountId(new AccountId(41L))
.targetAccountId(new AccountId(42L))
// ... 다른 여러 필드를 초기화
.build();
하지만 빌더 패턴을 사용하면 SendMoneyCommand에 필드를 새로 추가해야 하는 상황에서 빌더를 호출하는 코드에 새로운 필드를 추가하는 것을 잊을 수 있다. 물론 런타임에 유효성 검증 로직이 동작해서 누락된 파라미터에 대해 에러를 던지긴 하지만 컴파일 단에서 이끌도록 하는 것이 어떨까?
유스케이스마다 다른 입력 모델
각기 다른 유스케이스에서 동일한 입력 모델을 사용하고 싶을 수 있다. 예를 들어 ‘계좌 등록하기’와 ‘계좌 정보 업데이트’라는 두 가지 유스케이스를 생각해 보자. 두 가지 모두 거의 동일한 상세 정보가 필요하지만, 두 유스케이스에서 공유하지 않는 정보가 존재하는데 입력 모델을 공유할 경우 특정 속성들의 null 값을 허용해야 한다.
불변 커맨드 객체의 필드에 대해서 null을 유효한 상태로 받아들이는 것은 code smell이다. 하지만 더 문제가 되는 부분은 서로 다른 유효성 검증 로직이 필요해지는 것이다. 유스케이스에 커스텀 유효성 검증 로직을 넣어야 할 것이고, 이것은 비즈니스 코드의 관심사를 오염시킨다. 따라서 각 유스케이스 전용 입력 모델은 유스케이스를 훨씬 명확하게 만들고 다른 유스케이스와의 결합도 제거해서 불필요한 side effect를 발생하지 않게 한다.
비즈니스 규칙 검증하기
입력 유효성 검증은 유스케이스 로직의 일부가 아닌 반면, 비즈니스 규칙 검증은 유스케이스 로직의 일부이다. 그런데 언제 입력 유효성을 검증하고 언제 비즈니스 규칙을 검증해야 할까?
비즈니스 규칙을 검증하는 것은 도메인 모델의 현재 상태에 접근해야 하는 반면, 입력 유효성 검증은 그럴 필요가 없다.
입력 유효성을 검증하는 것은 구문상의(syntactical) 유효성을 검증하는 것이라고도 할 수 있다. 반면 비즈니스 규칙은 유스케이스의 맥락 속에서 의미적인(semantical) 유효성을 검증하는 일이라고 할 수 있다.
- ex) ‘출금 계좌는 초과 출금되어서는 안 된다. → 모델의 현재 상태에 접근해야 하기 때문에 비즈니스 규칙이다.
- ex) ‘송금되는 금액은 0보다 커야 한다. → 모델에 접근하지 않고도 검증될 수 있기 때문에 입력 유효성 검증으로 구현할 수 있다.
이러한 구분은 논재의 여지가 있지만 이러한 구분법의 장점은 특정 유효성 검증 로직을 코드 상의 어느 위치에 존재할지와 찾는 데 도움이 된다.
비즈니스 규칙 검증을 구현하는 좋은 방법은 도메인 엔티티 안에 넣는 것이다.
public class Account {
// ...
public boolean withdraw(Money money, AccountId targetAccountId) {
if (!mayWithdraw(money)){
return false;
}
// ...
}
}
- 규칙을 지켜야 하는 비즈니스 로직 바로 옆에 규칙이 위치하기 때문에 위치를 정하는 것도 쉽고 추론하기도 쉽다.
만약 엔티티에서 비즈니스 규칙을 검증하기가 여의치 않다면 유스케이스 코드에서 도메인 엔티티를 사용하기 전에 해도 된다.
package buckpal.application.service;
@RequiredArgConstructor
@Transactional
public class SendMoneyService implements SendMoneyUseCase {
// ...
@Override
public boolean sendMoney(SendMoneyCommand command){
requireAccountExists(command.getSourceAccountId());
requireAccountExists(command.getTargetAccountId());
}
}
- 유효성을 검증하는 코드를 호출하고, 실패할 경우 유효성 검증 전용 예외를 던진다.
- 사용자와 통신하는 어댑터는 이 예외를 에러 메시지로 사용자에게 보여주거나 적절한 다른 방법으로 처리한다.
더 복잡한 비즈니스 규칙의 경우에는 먼저 데이터베이스에서 도메인 모델을 로드해서 상태를 검증해야 할 수도 있다. 결국 도메인 모델을 로드해야 한다면 도메인 엔티티 내에 비즈니스 규칙을 구현해야 한다.
rich(풍부한) vs anemic(빈약한) 도메인 모델
도메인 모델을 구현하는 방법에서는 열려 있다. DDD 철학을 따르는 rich domain model을 구현할 것인지, anemic domain model을 구현할 것인가는 자주 논의되는 사항이다.
풍부한 도메인 모델
- 애플리케이션 코어에 있는 엔티티에서 가능한 많은 도메인 로직 구현
- 엔티티들은 상태를 변경하는 메서드를 제공하고, 비즈니스 규칙에 맞는 유효한 변경만 허용
- 유스케이스는 도메인 모델의 진입점으로 동작
빈약한 도메인 모델
- 일반적으로 엔티티는 상태를 표현하는 필드와 이 값을 읽고 바꾸기 위한 getter, setter 메서드만 포함하고 도메인 로직을 가지지 않는다.
- 도메인 로직이 유스케이스 클래스에 구현돼 있다는 것
유스케이스마다 다른 출력 모델
입력과 비슷하게 출력도 가능하면 각 유스케이스에 맞게 구체적일수록 좋다. 출력은 호출자에게 꼭 필요한 데이터만 들고 있어야 한다.
‘송금하기’ 유스케이스 코드에서는 boolean 값 하나를 반환했다. 이는 송금하기 맥락에서 반환할 수 있는 가장 구체적인 최소한의 값이다.
업데이트된 Account를 반환하고 싶을 수도 있다. 하지만 ‘송금하기’ 유스케이스에서 정말로 이 데이터를 반환해야 할까? 이 부분에 정답은 없다.
그러니 유스케이스를 가능한 한 구체적으로 유지하기 위해서는 계속 질문해야 하며, 의심된다면 가능한 한 적게 반환하자. 유스케이스들 간에 같은 출력 모델을 공유하게 되면 유스케이스들도 강하게 결합된다. 단일 책임 원칙을 적용하고 모델을 분리해서 유지하는 것은 유스케이스의 결합을 제거하는 데 도움이 된다. 따라서 도메인 엔티티를 출력 모델로 사용하지 않아야 한다.
읽기 전용 유스케이스?
UI에 계좌의 잔액을 표시해야 한다고 가정해 보자. 이를 위한 새로운 유스케이스를 구현해야 할까? 이 같은 읽기 전용 작업을 유스케이스라고 언급하는 것은 조금 이상하다.
‘계좌 잔고 보여주기’라고 부를 수 있는 특정 유스케이스를 구현하기 위해 요청한 데이터가 필요할 수도 있고 전체 프로젝트 맥락에서 이러한 작업이 유스케이스로 분류된다면 다른 유스케이스와 비슷한 방식으로 구현해야 한다.
하지만 애플리케이션 코어의 관점에서 이 작업은 간단한 데이터 쿼리다. 그렇기 때문에 프로젝트 맥락에서 유스케이스로 간주되지 않는다면 실제 유스케이스와 구분하기 위해 쿼리로 구현할 수 있다. 이를 구현하는 한 가지 방법은 쿼리를 위한 인커밍 전용 포트를 만들고 이를 쿼리 서비스에 구현하는 것이다.
package buckpal.application.service;
@RequiredArgsConstructor
class GetAccountBalanceService implements GetAccountBalanceQuery {
private final LoadAccountPort loadAccountPort;
@Override
public Money getAccountBalance(AccountId, accountId){
return loadAccountPort.loadAccount(accoutId, LocalDateTime.now()).calculateBalance();
}
}
쿼리 서비스는 유스케이스 서비스와 동일한 방식으로 동작한다. GetAccountBalanceQuery라는 인커밍 포트를 구현하고, 데이터베이스로부터 실제로 데이터를 로드하기 위해 LoadAccountPort라는 아웃고잉 포트를 호출한다. 이처럼 읽기 전용 쿼리는 쓰기가 가능한 유스케이스(커맨드)와 코드 상에서 명확하게 구분된다. 이러한 방식은 CQS or CQRS 같은 개념과 아주 잘 맞는다.
요약
도메인 로직을 원하는 대로 구현할 수 있도록 열어두었지만, 입출력 모델을 독립적으로 모델링한다면 side effect를 피할 수 있다. 물론 유스페이스 간 모델을 공유하지 않으므로 더 많은 코드 작업이 필요하지만 장기적으로 유지보수 측면에서 유용하다.