본 포스팅은 패스트캠퍼스 환급 챌린지 참여를 위해 작성하였습니다.
강의 내용
오늘 강의에서는 게시판 프로젝트의 마지막으로써 여태까지 프로젝트에 대한 정리 위주의 내용이었다. 예외 처리, 로깅 프레임워크, 모니터링 도구(CloudWatch, X-Ray, CloudTrail, Inspector, Config 등), CI/CD 도구들에 대해 언급해주셨고, 간단한 이론 중심의 강의로 각 기술의 개념과 종류를 소개하는 시간이었다. 특히 로깅 프레임워크 부분에서 Log4j, Logback, Log4j2, SLF4J 등 여러 프레임워크가 언급되었는데, 평소의 신경써본적이 없어서 각각의 차이점과 제대로 이해하고 싶어 추가로 정리해보았다.
Java 로깅 아키텍처 구조
Java 로깅은 추상화 계층(Facade)과 구현체(Implementation)로 분리된다. SLF4J는 표준 로깅 인터페이스를 제공하는 파사드이고, Log4j/Logback/Log4j2는 실제 로깅을 수행하는 구현체다.
// 코드는 SLF4J 인터페이스에만 의존
Logger logger = LoggerFactory.getLogger(MyService.class);
logger.info("Processing order: {}", orderId);
이런 설계 덕분에 런타임에 구현체를 자유롭게 교체할 수 있다.
의존성만 변경하면 되므로, 성능 최적화나 마이그레이션이 훨씬 쉬워진다.
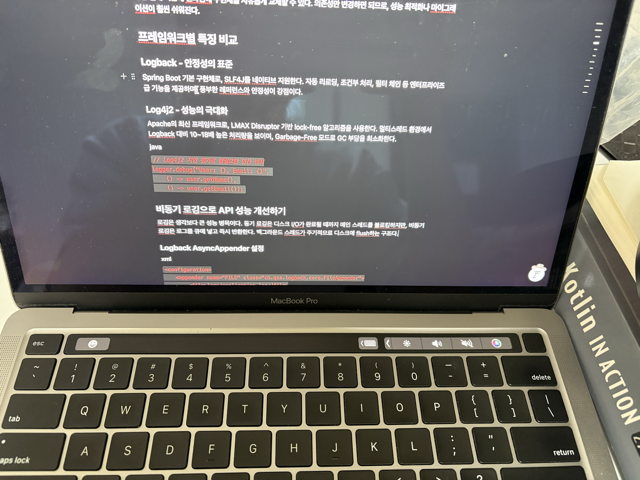
프레임워크별 특징 비교
Logback
- Spring Boot 기본 구현체로, SLF4J를 네이티브 지원한다.
- 자동 리로딩, 조건부 처리, 필터 체인 등 엔터프라이즈급 기능을 제공하며, 풍부한 레퍼런스와 안정성이 강점이다.
Log4j2
- Apache의 최신 프레임워크로, LMAX Disruptor 기반 lock-free 알고리즘을 사용한다.
- 멀티스레드 환경에서 Logback 대비 10~18배 높은 처리량을 보이며, Garbage-Free 모드로 GC 부담을 최소화한다.
// Log4j2 지연 평가로 불필요한 연산 방지
logger.debug("User: {}, Email: {}",
() -> user.getName(),
() -> user.getEmail());
비동기 로깅
로깅은 생각보다 큰 성능 병목이다. 동기 로깅은 디스크 I/O가 완료될 때까지 메인 스레드를 블로킹하지만, 비동기 로깅은 로그를 큐에 넣고 즉시 반환한다. 백그라운드 스레드가 주기적으로 디스크에 flush하는 구조다.
Logback AsyncAppender 설정
<configuration>
<appender name="FILE" class="ch.qos.logback.core.FileAppender">
<file>logs/application.log</file>
<encoder>
<pattern>%d{yyyy-MM-dd HH:mm:ss} [%thread] %-5level %logger{36} - %msg%n</pattern>
</encoder>
</appender>
<appender name="ASYNC_FILE" class="ch.qos.logback.classic.AsyncAppender">
<appender-ref ref="FILE"/>
<queueSize>5000</queueSize>
<discardingThreshold>0</discardingThreshold>
<includeCallerData>false</includeCallerData>
</appender>
<root level="INFO">
<appender-ref ref="ASYNC_FILE"/>
</root>
</configuration>
- queueSize: 버퍼에 담을 수 있는 로그 이벤트 수
- discardingThreshold: 큐가 꽉 찼을 때 오래된 로그 드롭 기준
- includeCallerData: false로 설정해 성능 향상 (스택 추적 비용 제거)
Log4j2 비동기 설정
Log4j2는 LMAX Disruptor를 사용해 더 높은 성능을 낸다고 한다.
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-log4j2</artifactId>
</dependency>- 별도의 의존성이 필요하며 기본 logback 의존성은 혹시 모를 충돌을 방지하기 위해 제거하는게 좋다.
<Configuration status="WARN">
<Appenders>
<File name="FILE" fileName="logs/app.log">
<PatternLayout pattern="%d{HH:mm:ss.SSS} [%t] %-5level %logger{36} - %msg%n"/>
</File>
<Async name="ASYNC_FILE">
<AppenderRef ref="FILE"/>
</Async>
</Appenders>
<Loggers>
<Root level="INFO">
<AppenderRef ref="ASYNC_FILE"/>
</Root>
</Loggers>
</Configuration>
비동기 로깅 벤치마크 인사이트
동시 요청이 있는 테스트 환경에서 비동기 로깅을 활성화하면 응답 시간 변동성이 최대 20~30%까지 줄어들었으며 , 특히 처리량이 높은 경우에 그렇다. 즉, 서비스에서 생성하는 로그가 많을수록 성능 이점이 커질 수 있다.


비동기 로깅은 성능 향상이 큰 장점이지만, 반드시 고려해야 할 단점들이 있다.
- 로그 유실 가능성: 애플리케이션이 갑자기 종료되면 큐에 남아있던 로그가 유실될 수 있다. 특히 크리티컬한 에러 로그나 감사 로그가 필요한 시스템에서는 치명적이다.
- (Graceful Shutdown이 구현되어야 한다.)
- 디버깅 복잡도 증가: 로그가 비동기로 기록되므로 실제 이벤트 발생 시점과 로그 기록 시점 사이에 지연이 생긴다. 멀티스레드 환경에서 로그 순서가 뒤바뀔 수 있어 장애 추적이 어려워질 수 있다.
- 메모리 오버헤드: 큐를 위한 추가 메모리가 필요하며, queueSize를 너무 크게 설정하면 메모리 압박이 생긴다. 트래픽 패턴에 맞는 적절한 크기 설정이 중요하다.
- 큐 오버플로우 처리: 큐가 꽉 차면 로그를 드롭하거나 블로킹해야 한다.
참고 출처
- https://medium.com/@bayusrihernogo/implementing-asynchronous-logging-in-spring-boot-for-better-api-performance-1141b93caf08
- https://sematext.com/blog/java-logging-frameworks/
- https://adjh54.tistory.com/391


https://fastcampus.info/4oKQD6b